I really like indexes. I wish fiction books had them, but I believe non-fiction books MUST have them, especially mine. I'm intrigued by the possibilities for indexes with ebooks, but wasn't able to wait for the fancy stuff to be ready for my new book about EPUB. So, I created my own.
I use InDesign to prepare my EPUBs. Curiously, InDesign won't export either the TOC or the index to its EPUB file. They simply don't appear, with or without links. So, I had to get creative.
The first problem was how to get the contents of my already created index out of InDesign. If you copy the index out to a text document, you don't get any of the formatting. You can export to Dreamweaver, and it will create an XHTML document, including everything but your TOC and index.
The solution is to copy the index and paste it into a new InDesign document. Then choose File > Export for... > Dreamweaver. You'll have successfully fooled InDesign into thinking the index was just normal text and it will create a nice XHTML file for you, with properly formatted index entries.
I'll leave it up to you to add the proper CSS so that your index looks snazzy.
The real trouble is how to make the links work. There's no way to know what the pagination will be like in an EPUB document. An EPUB can be viewed on all different size screens, and your readers can change the font size and thus change the pagination, as many times as they like. Page 23 in an EPUB might be half of page 16 in the print edition one day, and all of page 30 the next!
So, how do you link the index to the referenced pages without totally recreating the index entries one by one? (Not even an index lover like me is going to do that.)
My solution was to mark the actual physical print pages in the EPUB. This has two benefits. First, if ereaders ever get around to supporting the pageList function, I'll be able to use it to relate the print edition to the EPUB edition (which could be useful in classrooms, for example, to get everyone to the same content). For the record, Apple recommends the use of pageList, though I can't see that iBooks does anything with the information, at least not yet.
My book only has 192 pages, so I decided the fastest way to mark the beginning of each physical page in the EPUB was by hand, inserting
<span id="pxx"></span>, where xx is the appropriate page number. It certainly took a lot less time than creating a target for each and every index entry (which still wouldn't have solved the problem of compiling multiple references into a single entry with multiple page references). Next, I used GREP to convert my XHTML index entries into links to the now-marked pages.
The first step was to change the very few index entries that had numbers in the text itself. For example, I changed HTML5 temporarily into "HTMLfive" so that the 5 wouldn't be affected by my global changes later.
Since my EPUB has five separate XHTML files that might contain index entries, I had to use five different GREP expressions.
Here's the first one:
Search For:
( |–)(7|8|9|1[0-8])(,|</p>|–)(Which means, search for a string that starts with a space or an en dash, followed by either a 7, 8, 9, or a 1 followed by one of 0-8, and then followed by either a comma, closing p element or an en dash. Which means, in plainer english, find me any index entry number from 7-18 (the pages in my introduction). I limited it to numbers after a space or en-dash and before a comma, closing </p>, or en dash so as to not grab two-digit numbers within three-digit ones.
Replace with:
\1<a href="ePub-STTP-1.xhtml#p\2">\2</a>\3This Replace phrase references the three things we found in the Search phrase. The first was either a space or an en dash. The second is the page number, and the third is either a comma, closing p element or an en dash. And so we'll replace what we've found with either the space of the en dash, followed by the code for a link that references the XHTML document that contains pages 7-18 (the introduction), followed a hash symbol and the letter p, followed by the page number we found, followed by the end of the a element code, followed by the page number we found as the clickable text, followed by </a>, followed by the comma, closing p element, or en dash.
You have to run it twice because the first time it will get all the entries before an en dash and the second time it will get all the ones after it. But in my tests, it couldn't find the en dash if the search text was contained in the previous replacement text (which makes sense).
And poof, all the index entries for the introduction are done.
Now, we'll do the index entries for the first chapter, which in this example, goes from page 19 to 44.
We'll Search for:
( |–)(19|2[0-9]|3[0-9]|4[0-4])(,|</p>|–)The only thing different here is the page numbers we're looking for. Here we want 19, or a 2 followed by 0-9 (that is all the 20's), or a 3 followed by 0-9, (the 30's), or a 4 followed by 0-4 (from 40–44).
And we'll replace it with:
\1<a href="ePub-STTP-2.xhtml#p\2">\2</a>\3Which is the same as the first replacement text, except that this time it's the XHTML file that contains pages 19-44.
I won't bore you with the three remaining pairs of search and replaces, although I'm happy to share them if you need them.
Of course, you may need to adjust your search patterns to match your own index's formatting. And if you have cross references (see this topic, or see also that topic), you should change those into links as well.
Then I changed those few index entries that had numbers in the text (like HTMLFive) back into numbers (HTML5).
I was done with the links themselves, and all that was left was to finish off the XHTML code (the head section, closing body and html tags, etc.), and then add it to the content.opf and toc.ncx files (as described in my book).
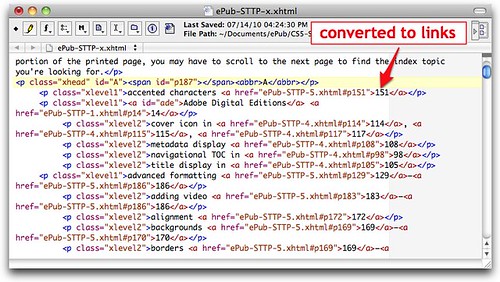
Once compiled into the EPUB it looks like this:
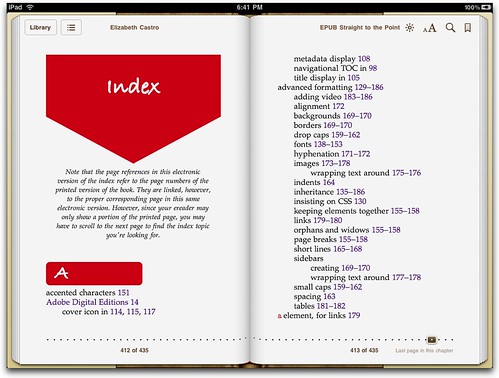
Find the entry you're interested, click the page number, and away you go!
This is not a perfect system. Since any ereader might divide what used to be a print page into various ereader pages, showing the beginning of the printed page may or may not include the referenced topic. The reader may have to turn an electronic page to find the topic. I added a note to the index to explain this.
Still, it's pretty good. It's lovely to be able to follow contextual index entries and find what you're looking for without having to search, say, every instance of "content.opf".
By the way, I have posted the complete index for my new EPUB book. (The links are not live on the website, since they'd have no place to go.)


You should give xslt a shoot on this kind of problems. It is more sophisticated and reusable and in the end much faster than a sequence of grep steps. I know that starting with XSLT can be frustrating, but the benefits are worth the trouble.
ReplyDeleteHey Stefan: You're probably right. The problem is that most folks can't deal with figuring out an XSLT processor, but they do have InDesign and a text editor with GREP. (I wrote about and experimented a bunch with XSLT in my XML book.)
ReplyDeleteVery interesting approach. In the past I have used InDesign's search/find/replace functions to create HTML pages. ;-)
ReplyDeleteForgive the dumb question, but does this approach assume starting from a linked index built in InDesign?
ReplyDeleteI'm working with a 600 page reference work; its index is just a plain-text list of terms and the corresponding print page number--no reference to index levels. So I'm not sure how you got the initial XHTML file with the level 1 tags, etc. Is that something that has to be built in from the beginning?
Not a dumb question at all, I totally skirted how I had built the index. Yes, I generated it with InDesign.
ReplyDeleteIn your plain-text list, is there anything that distinguishes one level of entry from another, say number of tabs or spaces at the beginning of the line? If so, you can search for that to add the XHTML formatting.
I have done this in the past to convert plain-text indexes to HTML.
Hope that helps. Let me know if you need more.
a free mac text-editor that does grep is
ReplyDelete"texedit" -- note that there are only _2_
instances of the letter "t" in the name,
not _3_ like in the apple-provided app.
the "tex" stands for "texas"...
i mention this here now because texedit
does grep, but also because you were
tweeting for a free mac text-editor, and
i've found texedit to be my total favorite.
i've paid the $20 shareware fee _twice_,
and still call it a phenomenal bargain...
-bowerbird
>> The reader may have to turn an electronic page to find the topic.<<
ReplyDeleteThis is way off. If the original page was quite large, and text dense, say an academic research book, and the 7" Kindle set to a large font, then the bottom of the original page could easily be 15 Kindle page turns away from the top.
This is absolute madness! I have a 500+-page book with an extensive index (created in that most heinous program, MS Word) and more than 1,200 endnotes. The PDF has been made into an Adobe Digital Reader e-book. And I would like an epub version to offer on Amazon, Barnes & Noble, possibly the iBookstore. But I haven't found anything that leads me to believe I can convert the book into anything resembling the original in terms of the text's documentation (the notes) and index--without massive investments of time, hassle, learning new software, hoping it will prove useful after learning it, etc. Isn't there anything more practical out there?
ReplyDelete@John-Manuel InDesign CS5.5 is a bit better than CS5, certainly words beyond Word. But you're right, the tools really need to get a lot stronger and right now we're still having to do a lot by hand. Still, it can be done.
ReplyDeleteJust a heads-up from the land of Windows: Notepad++ doesn't seem to recognize the | (pipe, meaning "or") character in GREP. Ain't that handy? After much flailing around, I found GREPwin, which is NOT a text editor, but one of a number of programs that do nothing *but* grep searches. It worked just fine. Use it in conjunction with a text editor. Several other programs had maddening limitations that rendered them useless for this sort of job. Example: A completely separate program, Windows GREP, recognizes GREP in searches -- but NOT in replacements! Says so (buried deep) in the program's help docs. Go figure.
ReplyDeleteThanks, Roger, that's very helpful.
ReplyDeleteAt what point do you add the page code span id="pxx"?
ReplyDeletein the xhtml (epub) or in the indesign file (on the page somewhere)?
cheers
Dave
I add it to the EPUB files themselves. I know others have experimented with attempting to add it in InDesign, but I haven't seen a good system myself yet.
Deleteah ok so, you manually work out where a page end and begins... ?
ReplyDeletecheers
Dave
I am truly grateful for your resources; they have been a great help for me, someone quite UNfamiliar with HTML!
ReplyDeleteI read your blog "Creating an Index for EPUB with InDesign and GREP" but am struggling with the following error when I test the file on an iPad: "error on line 22 at column 35: Specification mandate value for attribute a". I would greatly appreciate any help with exactly where I should place the "a href" string and closing "a" when there is already a span field, which includes class and style, just before the page number.
Thank you! ~ Lisa
Can you post one of the entries, including the link code? You might need to encode the less than symbol with < (ampersand, l, t, semicolon)
DeleteLiz, thanks for the quick reply! I am so new at this I am not even certain what "encode the less than symbol" means. Substitute?
Delete&p class="index-entry-02"&12 &span class="index-page-no-" style="font-size:1em;" a href="WhatDoYouThinkEBook-13.html#p29"&29&/a&&/span&&/p&
Lisa
Blogger will interpret the code unless you substitute (ampersand, l, t, semicolon) for a less than symbol and (ampersand, g, t, semicolon) for a greater than symbol.
DeleteSo, to get this: <p> (and NOT an actual paragraph)
in the comments, I had to type ampersand, l, t, semicolon, p, ampersand, g, t, semicolon (without the commas, of course).
Does that make sense? Try again?
Oh my head hurts! Here goes:
Deleteampersand l t semicolon p class="index-entry-02" ampersand g t semicolon 12 ampersand l t semicolon span class="index-page-no-" style="font-size:1em;" a href="WhatDoYouThinkEBook-13.html#p29" ampersand g t semicolon 29 ampersand l t semicolon /a ampersand g t semicolon ampersand l t semicolon /span ampersand g t semicolon ampersand l t semicolon /p ampersand g t semicolon
Oh dear. One last time and I think we'll have it. Use the symbols & and ; instead of the words, and don't put any spaces.
Delete<pclass="index-entry-02">12<spanclass="index-page-no-"style="font-size:1em;"ahref="WhatDoYouThinkEBook-13.html#p29">29</a></span></p>
DeleteThere we go! I see a bunch of typos. There should be a space between p and class, and between span and class, and between a and href. And I don't see a closing greater-than sign at the end of the opening span tag, or an initial less than sign at the beginning of the a. I'm guessing that the search and replace strings were not exact (which they must be). It should look like this:
ReplyDelete<p class="index-entry-02">12<span class="index-page-no-" style="font-size:1em;"><a href="WhatDoYouThinkEBook-13.html#p29">29</a></span></p>
Liz, this did it! In the ePub on the iPad, I have the page number 29 beside the Scripture reference and it is linked to actual page 29. Whew! . . . Next is to format the link to be in italics. . . . Maybe.
DeleteThank you SO MUCH!
Lisa
Hi Liz – I was just doing a search for a particular GREP indexing problem I have in InDesign, and discovered this phrase on your page:
ReplyDelete'which still wouldn't have solved the problem of compiling multiple references into a single entry with multiple page references'
That is exactly the problem I'm trying to solve! In other words if I have the entries
Jack 23
Jack 24
I want the GREP Find and Replace to turn them into
Jack 23, 24
I can't seem to work out how you meant this could be done (I'm quite new to GREP)... can you point me in the right direction?
thanks in advance for any help!
Chris
This is helpful, but I'm compiling a SCRIPTURE index, which means literally every single index entry has numbers in it. Aye carumba! Still, while I have to go through and replace each item individually (because "Replace All" would nuke my index entries, too), this is still *way* faster than typing each link out by hand, though GREPs are still kind of esoteric to me. It would be nice if Microsoft Word, Adobe, and the other powers-that-be would come up with a GUI for this stuff.
ReplyDeleteDear Liz,
ReplyDeleteThe FIND part of your advice works perfectly. However, when I use the replace that you recommend, Adobe Dreamweaver is literally inserting "\1" etc. instead of inserting the string from the Find. I have "Use regular expression" checked (the Find wouldn't work without it!). I recognize that what \1, \2, and \3 are supposed to do is take the 3 strings from the Find function and insert them. But I'm just getting a \1, \2, and \3 inserted instead. What am I missing?
Thanks,
David
I don't have DreamWeaver so I can't check, but it may just be that it uses a different syntax to identify the replacement text... for example, some programs use a $ instead of the \. I would check their documentation (or ask on Twitter :)
DeleteBingo! You nailed it. I don't have any kind of decent list of GREP. And you just blew my mind by indicating that not all programs use the same expressions for the same thing. What is the deal with nothing being standardized on the Web!? I say next presidential election, we all vote for the W3C! They'll get things straightened out around here! <g>
Delete